

熱線電話:0755-23712116
郵箱:contact@shuangyi-tech.com
地址:深圳市寶安區沙井街道后亭茅洲山工業園工業大廈全至科技創新園科創大廈2層2A
在機器學習中,經常聽到一個詞:“模型訓練”,不禁疑惑:模型是什么東西?怎么樣訓練的?訓練后得到的結果是什么?
下面用圖簡單描述個人理解:
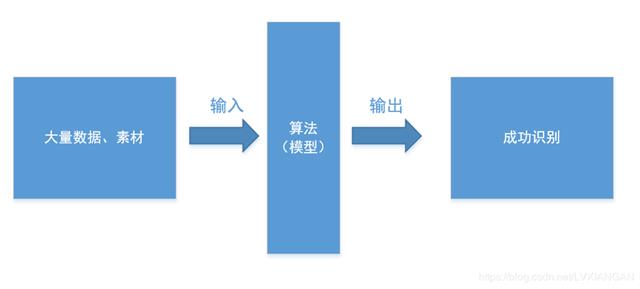
在人工智能中,面對大量用戶輸入的數據/素材,如果要在雜亂無章的內容準確、容易地識別,輸出我們期待輸出的圖像/語音,并不是那么容易的。因此算法就顯得尤為重要了。算法就是我們所說的模型。
當然,算法的內容,除了核心識別引擎,也包括各種配置參數,例如:語音智能識別的比特率、采樣率、音色、音調、音高、音頻、抑揚頓挫、方言、噪音等亂七八糟的參數。成熟的識別引擎,核心內容一般不會經常變化的,為實現”識別成功“這一目標,我們只能對配置參數去做調整。對于不同的輸入,我們會配置不同參數值,最后在結果統計取一個各方比較均衡、識別率較高的一組參數值,這組參數值,就是我們訓練后得到的結果,這就是訓練的過程,也叫模型訓練。
所以:
模型 = 算法
訓練 = 為達成高識別率的目標,使用大數據,找出最優配置參數的過程
結果 = 確定參數配置,實現高識別率
熱線電話:0755-23712116
郵箱:contact@shuangyi-tech.com
地址:深圳市寶安區沙井街道后亭茅洲山工業園工業大廈全至科技創新園科創大廈2層2A

<strike id="wo42y"></strike>